Rolf Todesco
Large Language Model
oder der linguistische Backturn
[ zurück ]
[ Stichworte ]
[ Die Hyper-Bibliothek ]
[ Systemtheorie ]
[ Meine Bücher ]
[ Meine Blogs ]
Als Large Language Model bezeichne ich ein sprachliches Konstrukt, das im Zusammenhang mit ChatGPT verwendet wird. Ich nehme an, dass es sich bei diesem Ausdruck um eine Wortschöpfung von ChatGPT handelt. Ich weiss nicht, wie ich den Ausdruck im Sinne des Schöpfers interpretieren müsste. DeepL beispielsweise "weiss" es auch nicht und gibt deshalb verschiedene Varianten zwischen "Grosses Sprachmodell" und "Modell für große Sprachen". Natürlich könnte ich annehmen, dass es sich um einen Eigennamen handelt, der dann logischerweise - wie etwa Karl der Grosse - nichts über die bezeichnete Sache sagen würde, ausser wie sie genannt wird. Ich nehme hier aber an, dass es sich um eine Bezeichnung handelt, die die referenzierte Sache wenigstens ansatzweise umschreiben soll. Diese Annahme werde ich später begründen. Ich nehme überdies an, dass nicht LLM sondern ChatGPT als Modell eines sprechenden Menschen aufgefasst wird, dass LLM eher für eine Theorie hinter dem ChatGPT steht.
Ich kritisiere zunächst die Redeweisen, mit welchen in diesem Kontext über einen Computer gesprochen wird.
Anschliessend beobachte ich den rationalen Kern dieser Redeweisen, in welchen ich in einen linguistischen Backturn erkenne. Die Sprachauffassung von N. Chomsky hat offensichtlich ausgedient, auch wenn das philosophische Paradigma gemäss T. Kuhn erst mit dem biologischen Sterben der jeweiligen Vertretern aussterben mag - noch leben ja viele Sprachphilosophen.
|
Large und Language sind schlicht blöd gewählte Ausdrücke. Ein grosses Modell wäre räumlich gross, wie etwa das Atomium in Brüssel. Gross kann sich dabei auch auf den Massstab beziehen. In der beim LLM verwendeten Redeweise ist wohl eher jene geistige Grösse gemeint, die Ali Muhamed zum Grössten machte; ChatGPT schlägt ja die Konkurrenz wie es ehedem der Boxer tat. Der Ausdruck Language dient - als Hypostasierung von Sprechen - generell als Platzhalter für "ich weiss nicht, was ich meine". Darauf werde ich zurückkommen.
Der Ausdruck Modell steht gemeinhin - auch wenn ihn die Mathematiker wie die meisten Wörter anders verwenden - für einen hergestellten Gegenstand mit der Gegenstandsbedeutung, den modellierten Referenten in gewissen Hinsichten darzustellen. Modelle sind aspektspezifisch isomorph, also "dreidimensional" körperhaft. Eine Modelleisenbahn beispielsweise zeigt, wie die modellierte Eisenbahn in massstäblicher Verkleinerung aussieht. Sie kann überdies auch zeigen, wie sich die Eisenbahn bewegt und wie sie angetrieben wird. Das Modell ist weder eine Zeichnung noch eine Beschreibung, es ist ein Artefakt, das im primitivsten Fall - wie etwa beim Atomium - lediglich die Gestalt des Referenzobjektes zeigt, im entwickelteren Fall aber - wie bei der Modelleisenbahn - auch Aspekte von dessen Verhalten.
|
![bild]()
|

Bildquelle: Wikipedia
|
Entscheidend ist der Unterschied zwischen einem Modell, das als Abbildung fungiert, und der Abbildung des Modells. Umgangssprachlich unterscheide ich sehr oft nicht zwischen dem Bild und der abgebildeten Sache. Ich sage: "Das ist eine Pfeife", wenn ich ein Bild von einer Pfeife sehe. R. Magritte sagte: "Ceci n’est pas une pipe". Ich kann das Modell zeichnen oder beschreiben. In beiden Fällen zeigt die Abbildung nicht, ob ich das Modell oder den modellierten Gegenstand abgebildet habe. Die Zeichnung einer Modelleisenbahn sieht aus wie die Zeichnung der entsprechenden Eisenbahn. Ich kann auch die richtige Eisenbahn mit ganz wenigen Strichen darstellen. Das Modell stellt eine eigenständige Repräsentation mit einer eigenen Funktionalität dar, die darin besteht, dass ich mit Modellen repräsentierend spielen kann. Eine Modelleisenbahn kann ich auf Schienen über Weichen fahren lassen, wozu sie wie ihr Vorbild Raum und Zeit benötigt. Zeichnungen und Beschreibungen bewegen sich nicht, also auch nicht in der Zeit.
Wenn ich das Herz als Pumpe bezeichne, sage ich damit, dass ich eine Pumpe als Modell für das Herz verwende. Und wenn ich das Gehirn als neuronales Netzwerk bezeichne, verwende ich eine elektrische Maschine als Modell für das Gehirn. Dabei ist aber das neuronale Netzwerk, nicht dessen Beschreibung das Modell. Wenn ich ein Mechanismus - was bei vielen Modellen der Fall ist - in einer Erklärung verwende, bezeichne ich ihn als System.
Das Referenzobjekt des LLMs ist im exemplarischen Fall der Chatbot ChatGPT, also ein Computer, mit welchem ich Texte generieren kann. A. Turing und J. Weizenbaum haben bereits sehr früh darüber geschrieben, was man mit solchen Computern - ausser Text generieren - auch machen könnte. Man könnte sie als intelligente Wesen verkaufen. Sie würden dann als Modelle für jene Menschen fungieren, die als Intelligenzia klassifiziert werden. Ersterer hat ein Kriterium für solche Maschinen geliefert, letzterer hat sogar einen solchen Computer programmiert, wobei seine Maschine, der er den sinnigen Namen Eliza gab, noch sehr einfach gestrickt war. Eliza simuliert Gesprächspartner, unter anderem relativ erfolgreich einen Psychotherapeuten, weil dessen Gesprächsbeiträge relativ einfachen Regeln folgen. Relativ zur Eliza kann das "large" in LLM auch "viel mehr" bedeuten, nämlich dass ChatGPT viel mehr verschiedene Sätze produzieren kann als im restringierten Code der Eliza vorkommen.
Ich unterscheide Modelle, bei welchen ich Referenzobjekt und Modell sinnlich wahrnehmen kann, von Modellen, bei welchen ich das Referenzobjekt selbst nicht wahrnehmen kann. Eine Modelleisenbahn etwa kann ich neben eine Eisenbahn stellen und beide in derselben Art wahrnehmen. N. Bohr's Atom-Modell kann ich nur als Modell betrachten, sein Referenzobjekt entzieht sich meiner Betrachtung. Indem ich das Bohr-Modell als Modell bezeichne, sage ich, wie ich mir das Referenzobjekt figürlich vorstelle.
Entwickelte Modelle sind Automaten, also geregelte Maschinen oder Geräte, die als Modelle komplizierte Verhaltensweisen ihrer Referenzobjekte zeigen. ChatGPT ist eine Maschine, die kompliziertes Verhalten zeigt. Als Maschine verwende sie wie andere Werkzeuge, um etwas herzustellen. Mit dem ChatGPT stelle ich Texte her, also grammatikalisch geordnete Mengen von Schriftzeichen.
Maschinen haben eine Funktionsweise, die ich beschreiben kann. Die Beschreibung der Funktionsweise dient mir als Erklärung des Phänomens, das ich mit der Maschine erzeugen kann. Ich kann mich fragen, wie der Text entsteht, den ich mit dem ChatGPT herstelle. In diesem Fall betrachte ich den ChatGPT als Blackbox und beschreibe dann deren Funktionsweise. Heron von Alexandria hat beispielsweise den alten Griechen das Phänomen erklärt, dass sich die Türe des Tempels öffnete, wenn der Priester auf dem Altar vor dem Tempel ein Feuer angezündet hat. Er hat dazu eine unterirdische Dampfmaschine konstruiert und deren Mechanismus beschrieben. Seine Erklärung, wonach der durch das Feuer erzeugte Dampf Wasser in einen Behälter drückt, durch dessen Gewicht dann Seilwinden angetrieben werden, die mit den Tempeltüren verbunden sind, macht recht viele physikalische Voraussetzungen. Aber ich kann die Maschine herstellen und jenseits jeder Physik prüfen, ob ich damit die Türen öffnen kann. Wenn ich in der heutigen Welt durch eine sich automatisch öffnende Türe gehe, frage ich mich normalerweise nicht, wie das funktioniert. Ich unterstelle einfach, dass eine elektrische Maschine mit Lichtschranken im Spiel ist, deren Funktionsweise ich im Prinzip - wie die Maschine von Heron - verstehen könnte.
Mit dem ChatGPT stelle ich Texte her. Ich will hier davon absehen, dass die Texte auch am Bildschirm erscheinen oder durch andere Maschinenteile vertont vorgetragen werden können. Ich kann die Texte auf Papier ausdrucken. Dann sind die Schriftzeichen materielle Gegenstände mit einer je bestimmten Form, beispielsweise geronnene Tinte in der Form eines "a". Text kann ich auch mit einem Bleistift herstellen. Ich kann Schriftzeichen aus Graphit formen. Die beiden Verfahren sind augenfällig verschieden, auch wenn das Resultat ebenso augenfällig das gleiche ist. In beiden Fällen schreibe ich. Ich verwende verschiedene Werkzeuge.
In beiden Fällen kann ich mich fragen, wie die jeweiligen Schriftzeichen hergestellt werden. Was teile meines Körpers machen, wenn ich schreibe, erkläre ich mir anhand der Operationen, die ich durch die Maschine ausführe, mit der ich Schriftzeichen herstelle. Die Maschine dient mir so als Modell. Sie ist kein Modell von mir, sondern ein Modell, das ein sehr spezifisches Verhalten meines Körpers modelliert, wodurch mein Körper als entsprechende Maschine erscheint, oder eben als etwas, was wie diese Maschine funktioniert.
Das Schreibwerkzeug entwickelt sich vom Stab, mit welchem ich im Sand zeichne, zum Bleistift, zur Schreibmaschine bis hin zum Computer. Jede Entwicklungsstufe zeigt, was ich zuvor noch selbst machen musste. Die Schreibmaschine zeigt, dass ich davor die Schriftzeichen selbst formen musste, die elektrische Schreibmaschine zeigt, dass ich dazu - auch wenn ich es kaum gemerkt habe - Kraft brauchte, um die Masse des Bleistiftes zu bewegen.
Wenn ich Text mit einem PC herstelle, passiert oft etwas eigentlich Erstaunliches - auch wenn ich darüber nicht staune. Wenn ich beispielsweise 2 + 3 tippe, erscheint 5, also ein Schriftzeichen, das ich gar nicht getippt habe. Das passiert bei der Schreibmaschine nie. Wenn ich vergessen würde, dass mein Computer eine elektrische Maschine ist, könnte ich sagen, dass er (oder sie) etwas zu meinem Text beiträgt, dass er mitschreibt. Ich könnte die 5 sogar als Antwort auffassen, die er mir auf meine Frage, wieviel zwei und drei ergibt, gibt. Manchmal schlägt mir mein Computer vor, bestimmte Wörter anders zu schreiben. Ich könnte sagen, dass er viel weiss und viel kann oder eben dass er einen Homunkulus enthält, der viel weiss oder intelligent ist. Das macht in meinem Bekanntenkreis aber erstaunlicherweise niemand.
Der Computer ist ein Automat, der idiotischerweise Computer oder Rechner genannt wird, obwohl er natürlich nicht rechnet. Was hätte er davon, wenn er rechnen würde? Ich könnte ihn eben so gut Antworter nennen. Im Ausdruck ChatGPT steckt ja ausser der Idee eines Gespräches (to chat) auch die Idee eines Transformers, der eben Text herstellt, wie wenn er der Homunkulus wäre. Aber Computer stellen natürlich auch keine Texte her. Ich stelle Texte mit einem Computer her. Ich rechne mit einem Rechner. Und normalerweise weiss ich im Unterschied zum Computer, wozu ich das mache.
Die Texte, die - seit kurzem - mit ChatGPT hergestellt werden, scheinen nicht nur mir ausserordentlich erstaunlich. Es sind wohlgeformte Sätze, die sich wie Antworten oder sogar Abhandlungen zu beliebigen Fragen lesen lassen. Ich staune also nicht nur darüber, dass ich mit Computern Schriftzeichen herstellen kann, sondern auch darüber, dass ich Anordnungen von Schriftzeichen herstellen kann, die ich als für mich sinnvolle Sätze lesen kann, ohne dass ich diese Sätze je auf dieser Maschine getippt habe. Ich sehe tautologischerweise wieder die Blackbox und frage mich, wie sie funktioniert. Und da ich auch wohlgeformte Sätze schreibe, erscheint mir diese Blackbox als Modell, das zeigt, wie ich wohlgeformte Sätze herstelle. Ich beschreibe dabei, wie die Maschine, die ich als Modell verwende, funktioniert.
|
Ich habe bisher nicht beschrieben, was in einem Computer passiert, wenn er auf meine Eingabe "2 + 3 =" eine 5 ausdruckt. Ich hab nur gesagt, das der Computer nicht rechnet. Ich will hier auch nicht erklären, was technisch genau passiert, aber klar ist, dass ich dabei eine Folge von Zuständen der Maschine beschreiben würde, was gemeinhin in Computerprogrammen geschieht. Die Programme sind Beschreibungen, keine Modelle. Der Computer dagegen ist ein hergestellter Automat, der diese Zustände durchlaufen kann. Die Eingabe "2 + 3 =" bewirkt, wenn der Computer in einem bestimmten Zustand ist, dass in einem Bauteil des Prozessors, den man Halbaddierer nennt, bestimmte Schalter in Form von Transistoren geöffnet oder geschlossen werden, wodurch bestimmte Ströme fliessen und andere eben nicht. Auf diese Weise nimmt ein bestimmtes Register einen bestimmten Zustand an, was im weiteren bewirkt, dass beispielsweise auf einer Art Schreibmaschine eine 5 auf ein Farbband geschlagen wird, wodurch das Schriftzeichen auf dem Papier hergestellt wird.
|
![bild]()
|

Bildquelle: Wikipedia
|
Hier geht es nur darum, dass ich die 5 als Antwort auf eine Frage deuten oder interpretieren kann, während die Maschine konstruktiv vorgesehene Zustände durchläuft, die mit Fragen und Antworten nichts zu tun haben. Wenn ich meinen Computer als Adressverwaltung benutze, gebe ich beispielsweise auf der Tastatur "Peter" ein und der Computer druckt dann "Huber, Müllerstr. 11, Zürich" aus. Ich nehme weder an, dass er weiss, wo Peter wohnt, noch dass er mit damit antworten will. Ich gehe viel mehr davon aus, dass die ausgedruckte Zeichenkette wie im einfacheren Fall die 5 eine Folge von durchlaufenen Operationen repräsentiert, auch wenn die Zeichenkette für mich eine Bedeutung hat.
Eliza von J. Weizenbaum druckt umfangreichere Schriftzeichenketten aus. Wenn ich "Hallo" eingebe, erscheint "Wie geht es Dir?", nach derselben Logik, wie in den anderen Fällen "5" oder "Huber" erscheint. Ein wichtiger Punkt ist, dass es sich in diesen Fällen um denselben Automaten in verschiedenen Zuständen handelt. Mit dem Wort Computer bezeichne ich programmierbare Automaten mit Ein- und Ausgabegeräten, die ich zur bedingten Herstellung von Schriftzeichenketten wie beispielsweise "5" oder "Huber" benutzen kann. Computer erfüllen auch andere Funktionen, was hier nicht interessiert. Dagegen interessiert hier die inverse Funktion des Computers, die darin besteht, einen Benutzer zu "steuern", ihn also mittels erwartbaren Ausgaben zu bestimmten Eingaben zu veranlassen. In einer Adressverwaltung gebe ich beispielsweise in einem bestimmten Feld "Peter" ein, weil ich weiss oder erwarte, dass dann eine Zeichenkette am Bildschirm erscheint, die mich interessiert.
Die Steuerung des Benutzers kann ich als Modell dafür betrachten, dass die erwartbare Wahrnehmung mein Verhalten steuert. Wenn ich am Computer eine bestimmte Adresse sehen will, mach ich eine bestimmte Eingabe. Und wenn ich als Mensch etwas Bestimmtes sehen will, muss ich mich auch entsprechend verhalten. Wenn ich den Eifelturm sehen will, muss ich nach Paris fahren. Nach W. Powers kontrollieren Menschen mit ihrem Verhalten generell ihre Wahrnehmung.
Computer werden so konstruiert, dass sie verschiedene Verwendungen zulassen. Ich kann meinen PC als Rechengerät zum Addieren, als Adressenverwaltung oder als Eliza benutzen. Ich spreche von Software, weil ich mit dem Computer praktisch ohne Aufwand ganz verschiedene Funktionen erfüllen kann, wenn es dabei immer darum geht, Schriftzeichen herzustellen. Nägel einschlagen oder Getreide mähen kann ich mit dem Computer nicht. Dafür ist er nicht hergestellt worden.
Jetzt kann ich - weil ich das entsprechende Programm eingelesen habe - meinen Computer auch als ChatGPT nutzen. Auch dabei stelle ich Text her. Die Texte, die ich mit ChatGPT herstelle, sind kaum unterscheidbar von Texten, die ich selbst formuliere. Also stellt sich die Frage nach der Funktionsweise auf einer neuen Stufe. Das Phänomen ist dabei nicht mehr nur das Herstellen von Text, sondern das Herstellen von wohlgeformten Sätzen, die nicht wie im primitiven Fall von Eliza vorab eingegeben und abgespeichert wurden. Bevor ich die Funktionsweise des Mechanismus erläutere, will ich etwas genauer betrachten, was ich beim Herstellen von Text mache und wie sich diese Tätigkeit durch die Entwicklung der dabei verwendeten Werkzeuge verändert.
Werkzeuge stelle ich her, um jeweils bestimmte Tätigkeiten effizienter zu machen. Im Nachhinein kann ich durch die in einem Werkzeug aufgehobenen Tätigkeiten die jeweilige Tätigkeit begreifen, indem ich die konstruktiv vergegenständlichte Tätigkeit begrifflich rekonstruiere. In der damit verbundenen Entwicklung von Begriffen erkenne ich neben der Effizienzsteigerung einen sekundären Zweck der Technik. Artefakt dienen dem Begreifen. Bleistift, Schreibmaschine und Computer machen das Herstellen von Text effizienter und lassen mich - sekundär - begrifflich expliziter verstehen, was ich beim Textherstellen mache. ChatGPT ist das zur Zeit entwickeltste Werkzeug zur Textherstellung. Seine begriffliche Rekonstruktion zeigt am bestem, was ich beim Schreiben mache. Der sekundäre Zweck der Technik wird diesbezüglich hier zum Primat.
Das Herstellen von Texten folgt einer bestimmte Logik, die darin besteht, jeweils weitere Schriftzeichen, die zur verwendeten Schrift gehören, den bereits vorhandenen anzufügen, wobei jeder Text ein jeweils erstes Schriftzeichen hat, das als Anfang gesetzt wird. Die Schreibmaschine oder der Setzkasten eines Bleisatzes zeigen, dass auch der Leerschlag und Satzeichen wie Punkt und Komma als Schriftzeichen verwendet werden. In einem typischen Fall schreibe ich etwa einen deutschsprachigen Text und verwende dabei sinnigerweise die Schriftzeichen der deutschen Schrift, deren Token, ich beispielsweise innerhalb eines Bereiches auf einem Papier in Zeilen anordne, indem ich die Zeilen auf der linken Seite des Blattes beginne und die weiteren Zeichen rechts anfüge. Ich beginne jeweils eine neue Zeile, wenn ich auf der aktuellen nicht mehr genug Platz habe für die Zeichen bis zum nächsten Leerschlag oder Trennstrich. Die Anordnung in Zeilen ist für den Text ohne Relevanz, sie ist den Platzverhältnissen geschuldet, die dadurch begrenzt sind, dass das Papierblatt und die Schriftzeichen eine je bestimmte Grösse haben. A. Turing hat beispielsweise vorgeschlagen, Text auf einem endlos langen Band anzuordnen, so dass keine Zeilenumbrüche nötig sind. Das wäre für Menschen nicht sehr handlich, aber für die primitive Maschine, die er konstruiert hatte, war das gut.
Die Anordnung der Schriftzeichen erfüllt Bedingungen der jeweiligen Schrift. Diese Bedingungen bezeichne ich als Grammatik der jeweiligen Schrift. Ein Text ist ein deutscher Text, wenn er die deutsche Grammatik erfüllt. Als Grammatik bezeichne ich eine systematische Beschreibung der Bedingungen. Anhand der Grammatik beurteile ich, ob ein Text korrekt ist. Allerdings verwende ich hier das Wort Grammatik in einem spezifischen textbezogenen Sinn, den ich später im Rahmen einer Grammatologie behandle. Die konventionelle Grammatik, die von Subjekt und Objekt handelt, repräsentiert viel mehr Vorstellungen über den Menschen als über Text.
Wenn ich Text herstelle, kann ich die Grammatik mehr oder weniger berücksichtigen. Mein Text kann unterschiedlich korrekt sein. Sehr viele Texte enthalten Schreib- oder Tippfehler, ohne dass sie deswegen nicht als Texte erkannt würden. Unter bestimmten Umständen bin ich dazu angehalten oder gar gezwungen, mich an die Grammatik zu halten. Insbesondere in der Schule lerne ich grammatikalisch korrekte Texte zu schreiben, wobei unerheblich ist, was im Text zu lesen ist. Ein berühmtes Beispiel für einen Satz, der der Syntax genügt, ist: "farblose grüne Ideen schlafen wütend" und ein etwas weniger berühmter Satz, der das nicht tut ist: "ich essen gerner fleisch braten". Keiner der beiden Sätze genügt einer Grammatik, die Syntax und Semantik umfasst. Im zweiten Satz kann ich jenseits von Grammatik erahnen, worauf er verweisen könnte. Der zweite Satz zeigt, dass ich Text herstellen kann, auch wenn ich sehr wenig grammatikalische Kenntnisse habe und vielleicht gar nicht weiss, dass es Grammatik gibt. Kinder lernen ja sprechen, ohne etwas von Grammatik zu wissen, das sie sagen könnten. [ ]
Ein wesentlicher Aspekt des sogenannten linguistischen Turns, den N. Chomsky eingeleitet hat, der auch als Kognitivismus bezeichnet wird, besteht in der Vorstellung einer Art Grammatik, die den Menschen angeboren sei. N. Chomsky postulierte damit, dass Kinder eine Grammatik quasi in den Genen mitbekommen und nur deshalb sprechen lernen können. Er meinte, dass er so jenen Behaviorismus, den er B. Skinner unterstellt hatte, widerlegen zu können. Hier geht es aber nur darum, dass ich ohne weiteres Sätze formulieren kann, die andere verstehen können, ohne mich an die Grammitik zu halten, selbst wenn sie in meinen Genen wäre. Die Grammatik hilft mir beim Schreiben nicht, sie entscheidet nur, ob meine Tetxte grammatikalisch korrekt sind.
Ich gehe davon aus, dass der Schrift phylogenetisch gegenüber dem Sprechen das Primat zukommt, dass ich beim Sprechen also entwicklungsgenetisch gesehen Text vertone. In der ontogenetischen Entwicklung dagegen lerne ich das Sprechen vor dem Schreiben. Deshalb vergleiche ich hier das Textherstellen mit ChatGPT auch mit dem Sprechen, das ich als Ausdruck von implizierten Schriftzeichen begreife.(1) Als Muttersprache bezeichne ich eine Sprache, die ich weitgehend ohne Lehrerin lerne. Ich eigne mir als Kleinkind die Verwendung von Sprechgeräuschen an, indem ich sie nachahme. Dabei muss ich kein Ziel verfolgen und keine Vorstellung vom Lernen haben. Ich kann am Anfang meines Bemühens, solche Laute hervorzubringen, kaum wissen, wozu es gut wäre, wenn ich sprechen könnte. Ich will dabei auch nicht lernen, sondern tue es, so wie ich kauen oder gehen lerne. Es handelt sich um Verhaltensweisen, die gemeinhin im behavioristischen Sinn verstärkt werden, auch wenn ich vorab keinen Sinn darin sehen kann - und nicht dazu hergestellt wurde, es zu tun.
ChatGPT betrachte ich hier als Modell dafür, wie sich bestimmte Formulierungen durchsetzen oder wahrscheinlicher werden. Dass ich das Phänomen so formuliere, also das Hervorbringen von Formulierungen beobachte, ist durch den Mechanismus, den ich als Modell verwende, bestimmt. ChatGPT macht gute Formulierungen. Ohne dieses Modell würde ich andere Phänomene oder das jeweilige Phänomen anders beschreiben. Das Phänomen, das ich erkläre, wird durch die Erklärung, die ich gebe, bestimmt.
Mit ChatGPT modelliere ich nicht nur das Herstellen von Text, sondern auch, den Erwerb oder die Aneignung der Fähigkeit, sinnvolle und korrekte Sätze herzustellen. Die Redeweise, wonach ChatGPT trainiert wird, besagt, dass der Mechanismus nach seiner Erstellung noch keine Texte erzeugt, so wie ein Kleinkind, wenn es auf die Welt kommt, noch nicht sprechen kann. Bestimmte Formulierungen werden sowohl von ChatGPT als auch von einem Kleinkind zunehmend regelmässiger hervorgebracht und andere immer weniger. In einem gewissen metaphorischen Sinn werden beide trainiert, sie werden von anderen korrigiert, was in dieser Sichtweise als Training aufgefasst wird. Ein Standardbeispiel beim Kleinkind dafür ist, dass seine Mutter immer Hund sagt, wenn das Kind wauwau sagt, oder dass sie plötzlich Kuh oder Katze sagt, wenn das Kind Hund sagt. Diese Art des Trainings entspricht sehr genau dem von den Behavioristen beschriebenen Lernen.
Nebenbei bemerkt thematisieren diese Beispiele einzelne Wörter, statt das Sprechen in Sätzen. Das eigentlich gemeinte Lernen eines Kindes besteht aber ohnehin in einem selbst kontrollierten Üben, nicht einem Belehrtwerden, wie es später in der Schule für Zweitsprachenerwerb üblich ist. Als Kleinkind erkenne ich zunehmend besser, welche meiner Formulierungen auch von anderen verwendet werden. Dazu brauche ich keine Korrekturen, sondern Gespräche. Ich kann bei Kindern leicht beobachten, dass sie zunehmend besser erkennen, wozu sprechen gut ist, das sie zunächst nur nachahmen. Damit verbunden erkennen sie auch immer besser, welche Arten des Sprechens sich besser lohnen. Dazu brauchen sie weder Lehrer noch fremde Bewertungen wie Benotungen.(2)
Bestimmte Formulierungen verwendet ChatGPT wie ein Kleinkind immer häufiger, ohne das Geringste von Grammatik auch nur zu ahnen. Beide lernen Sätze zu sagen, zu denen sie keinerlei Deutungen haben. Das Kleinkind lernt im Nachhinein Situationen erkennen, in welchen das Sagen der Sätze in dem Sinne eine Konsequenz haben kann, als sein Leben sich davon abhängig verändert. Es hat davor schon gelernt, dass das Schreien manchmal zum Gestilltwerden führt. Die Mutter mag meinen, dass das Kleinkind schreie, um gestillt zu werden. Das Kleinkind lernt, dass bestimmte Verlautbarungen bestimmte Konsequenzen bedeuten und in diesem Sinne eine Bedeutung haben. Das Kleinkind lernt beispielsweise, dass das Wort Hund seinen Trainern nur passt, wenn ein bestimmtes Tier zuhanden ist, was es dem Wort selbst natürlich nicht entnehmen kann. Es bleibt ihm sein Leben lang schleierhaft, weshalb Hund ein besseres Wort als wauwau ist. Dafür gibt es keine Erklärung, aber es gibt gute - behavioristische - Gründe, das eine Wort statt des anderen zu verwenden. Deshalb schreibt auch ChatGPT eher von Hund als von wauwau, wenn dieses Raubtier gemeint ist.
ChatGPT entwickelt sich bezüglich zunehmend passenderer Sätze wie ein Kind ohne explizite oder gar angeborene - einprogrammierte - Grammatik im konventionellen Sinn. Mit der kognitivistische Idee einer Tiefenstruktur-Grammatik hat die Linguistik trotz enormer Bemühungen keine brauchbare Übersetzungssoftware hervorgebracht, geschweige denn, so etwas wie ChatGPT. Ich werde später darauf zurückkommen. Wichtig ist hier, dass ich Sprechen nicht nur ohne Grammatik lerne, sondern auch ohne die Bedeutung des Sprechens vorab zu kennen und ohne den Sätzen eine halbwegs verbindliche Bedeutung zuordnen zu können. Ich lernte wie ChatGPT Sätze wie "farblose grüne Ideen schlafen wütend" oder "ich essen gerner fleisch braten" zu sagen und ich lernte dabei, welche Lautfolgen gute Sätze sind, ohne einen Grund oder ein Kriterium für gute Sätze zu kennen. Wie ich die Sätze deute, spielt dabei auch noch keine Rolle. ChatGPT braucht auch keine Deutung der Sätze. Auch darauf werde ich zurückkommen.
Damit habe ich das Phänomen der Textproduktion, das ich hier beobachte, etwas umrissen, ohne auch nur ansatzweise zu erklären, was dabei passiert. Quasietymologisch steckt im Ausdruck Phänomen, dass es eine Erscheinung von etwas ist, von dem ich gerne wüsste, was weshalb so erscheint. Als Phänomen bezeichne ich das, wofür ich eine Erklärung suche. Im hier gegebenen Kontext suche ich ein Modell dafür, dass ich wohlgeformte Sätze hervorbringen kann.
ChatGPT dient mir als Modell, weil ich mit ChatGPT wohlgeformte Sätze hervorbringen kann, ohne diese Sätze selbst zu formulieren. ChatGPT ist kein gedankliches oder sprachphilosophisches Konstrukt, sondern ein Artefakt. Es ist ein materiell hergestellter Computer, dessen Funktionsweise ich in dem Sinne verstehen kann, dass ich ihn herstellen oder dessen Herstellung wenigstens rekonstruieren kann. Hier geht es vorerst nicht darum, die ChatGPT-Maschine herzustellen, sondern darum zu verstehen, was ich damit wie herstelle. Wenn ich weiss, was ich herstellen will, unterscheide ich verschiedene Verfahren. Wenn ich Text herstellen will, kann ich es von Hand oder mit einem Computer tun. Wenn ich ein Verfahren gewählt habe, habe ich festgelegt, wie ich den Gegenstand herstelle. Der Gegenstand und das Verfahren stehen in einer Beziehung.
Verfahren nenne ich das, was ich operativ beschreiben kann. Eine verbreitete Form von operativen Beschreibungen sind Rezepte. Nehme dieses und jenes, mache damit dies und das. In einer operativen Beschreibung steht, was ich tun muss, um ein bestimmtes Resultat zu erhalten. Anstelle eines Rezeptes kann ich auch beschreiben, was jemand tut, um das Resultat zu erhalten. In solchen Formulierungen ist das Rezept impliziert, ich müsste dasselbe tun. Verfahren sind für Interventionen offen, also nicht vollständig festgelegt, sondern modifikabel. Verfahren haben eine bezüglich der Operationen bestimmte Auflösung. Wenn ausschliesslich festgelegte Operationen gemeint sind, spreche ich nicht von Verfahren, sondern von Methoden. Einen Konstruktionsplan zu verwenden, ist ein Verfahren. Der Konstruktionsplan impliziert selbst ein Verfahren, er legt aber nicht die Operationen fest, sondern deren Resultate. Ein Computerprogramm dagegen ist eine exemplarische Beschreibung einer Methode.
Verschiedene Verfahren führen, wenn sie korrekt ausgeführt werden, zum gewünschten Gegenstand. Die Beschreibungen der Verfahren dienen als Erklärungen dafür, wie ein solcher Gegenstand entstanden sein könnte. Natürlich muss ich über ein anderes Können und über andere Werkzeuge verfügen, je nachdem, ob ich einen Text von Hand oder mit einer Maschine herstelle. In gewisser Hinsicht erklärt mir der Computer, welche Verfahren ich beim Schreiben von Hand impliziere, auch wenn ich dabei andere Operationen verwende. Umgekehrt kann mir aber der Handwerker nicht sagen, wie ich eine entsprechende Maschine konstruieren muss, durch die ich ihn ersetzen kann. Er hat zu seinen Tätigkeiten viel implizites Wissen, dass er nicht explizit machen kann.
"Bionik" nennt sich eine Lehre, die aus der Natur ableiten will, wie Maschinen konstruiert sein müssen. Ich lese alle dort aufgeführten Beispiele rückwärts: die Maschinen klären jeweils ein Stück Natur. Seit wir Flugzeuge bauen können, wissen wir besser, was ein Vogel beim Fliegen macht. Die Flugzeuge, die wirklich fliegen, sind aber kaum den Vögeln nachempfunden, wie unsinnig beispielsweise O. Linienthal auch immer darüber gesprochen hat. Und oft wird das neuronale Netzwerk, das im ChatGPT verwendet wird, als dem Hirn nachempfunden aufgefasst. Ich verwende es hier als Erklärung von Phänomenen, die ich umgangssprachlich gesprochen, dem Hirn zurechne.(3)
Ich beschreibe im Folgenden das Verfahren, dass im ChatGPT als Maschine aufgehoben ist, indem ich Aspekte der Funktionsweise erläutere. Auch hier will ich nicht näher auf die Technik selbst eingehen, sondern die Aspekte hervorheben, die ich im Modell verwende.
Die Funktionsweise von Systemen beschreibe ich jenseits ihres Milieus und mithin jenseits von Funktionen, die sie in ihrem Milieu haben. Eine Heizung etwa hat die Funktion, ihre Umwelt zu wärmen. Wenn ich die Funktionsweise der Heizung als System beschreibe, spielt deren Umwelt keine Rolle. Die Heizung funktioniert unabhängig davon, ob sie in der Wüste, am Nordpol oder im Keller eines Hauses steht. Wer ChatGPT wofür einsetzt, ist für dessen Funktionsweise ohne Bedeutung.
Die Funktionsweise beschreibe ich, indem ich beschreibe, welche Zustände des jeweiligen Mechanismus sich in Abhängigkeit welcher Bedingungen wie verändern, wobei ich natürlich nur konstruktiv beabsichtigte Prozesse einbeziehe. Dass Maschinen auch altern und rosten, gehört nicht zu ihrer Funktionsweise. Dass beispielsweise mein Fahrrad umso schneller fährt, je schneller ich mittels der Pedalen das Kettenritzel drehe gehört zur Funktionsweise. Dass dieses Verhältnis nicht konstant ist, kann ich mit einen Kettenwechselmechanismus erklären. Und dass der Kettenwechsel bei bestimmten Drehzahlen "automatisch" erfolgt, erkläre ich mit einem Schaltautomaten, den ich in diesem Fall noch gar nicht kenne. Ich kann Aspekte der Funktionsweise beschreiben, ohne deren technische Realisierungen zu kennen.
Die konstruktiv beabsichtigten Zustandsänderungen eines Mechanismus bezeichne ich als Operationen, die Menge der jeweiligen Operationen als Verfahren. Bei einer thermostatengeregelten Ölheizung wird die Ölzuflussmenge durch die Temperatur eines Thermometers geregelt. Die Regelung meiner Körpertemperatur erkläre ich mir anhand des Thermostaten, obwohl ich dieses Bauteil in meinem Körper nicht finden kann.
Beim ChatGPT unterscheide ich in Bezug auf die Herstellung von Text zwei Verfahren, die ich bereits angesprochen habe. Zum einen geht es darum, Schriftzeichen an andere Schriftzeichen anzufügen und zum anderen geht es darum, das jeweils nächste Schriftzeichen auszuwählen. Mit diesen beiden Verfahren beschreibe ich auch, was ich mache, wenn ich von Hand schreibe. Im Folgenden behandle ich das zweite dieser Verfahren, durch welches nicht nur Text, sondern wohlgeformte Sätze hervorgebracht werden kann.
Aufgrund einer bestimmten Funktionsweise von ChatGPT - die ich noch erläutern werde -unterscheide ich, ob ich einem Text beim Herstellen jeweils einzelne Schriftzeichen oder jeweils ganze Wörter anfüge. Bevor ich ChatGPT gekannt habe, habe ich mir dazu keine Gedanken gemacht. Ich habe angenommen, dass ich Wörter schreibe. Jetzt sehe ich die Sache etwas komplizierter. Darin erkenne ich vor allem auch ein Beispiel dafür, dass ich durch die Entwicklung der Werkzeuge meine begrifflichen Kategorien entwickle.
Jetzt erkenne ich, dass Text aus Sequenzen von Schriftzeichen besteht. Wörter gehören als Konzepte zur Schrift, nicht zum Text. Als Wörter bezeichne ich Buchstabenketten, die gemäss der Grammatik der jeweiligen Sprache zur Schrift gehören. Mit ChatGPT stelle ich - das ist ganz entscheidend - keine Wörter, sondern Text in Form von Schriftzeichen her, wobei eines der Schriftzeichen der Leerschlag ist. Wenn ich den Text dann unter dem Gesichtspunkt von Schrift betrachte, kann ich Wörter sehen, die durch Leerschläge oder Satzzeichen - die auch Schriftzeichen sind - getrennt sind. Wörter kann ich aber nur erkennen, weil die Schriftzeichen durch ChatGPT nicht zufällig ausgewählt werden. Würden die Zeichenkette aus zufällig gewählten Schriftzeichen wie beispielsweise "hfdfhö weu kdvös dfdlkfd" bestehen, würden sie keine Wörter (einer mir bekannten Sprache) repräsentieren.
Wörter sind wie die Schriftzeichen, aus welchen sie bestehen, materielle Artefakte, sie dienen als Zeichenkörper. Ich unterscheide Wörter und Worte. Als Worte bezeichne ich Symbole, die für etwas stehen und Wörter als Zeichenkörper verwenden. Schriftzeichen sind keine Symbole, sie verweisen auf nichts. Dass ich materielle Gegenstände als Zeichen für etwas anderes verwenden kann, ist von Text und Schrift unabhängig der Fall und hier vorerst nicht Thema.
Beim Sprechen erzeuge ich kontinuierliche Tonfolgen, die Text repräsentieren, obwohl das - wie bei einem Digital-Analog-Wandler (ein CD-Konverter) - nicht zu hören ist. Ein Kleinkind lernt anfänglich Wörter zu sagen. Es macht nicht nur keine Sätze, die Wörter stehen auch für nichts. Es sind zunächst Nachahmungen von Geräuschen, jenseits davon, dass sie Text repräsentieren. Das ich beim Sprechen und beim Schreiben in meiner subjektiven Wahrnehmung Worte verwende, ist von den Trägern der Bedeutungen unabhängig. Sprechen und Schreiben verwende ich hier also in einem sehr spezifischen Sinn für die Herstellung von Text, was ich beim Schreiben - egal wie ich das Wort deute - natürlich immer mache.(4)
Ich erläutere jetzt, wie ich mit ChatGPT das jeweils nächste Schriftzeichen wähle, respektive, wie der Mechanismus dabei funktioniert. Ich beschreibe aber zunächst das Verfahren ohne mich um den Mechanismus und dessen Operationen zu kümmern. Das Verfahren wurde bereits von unzähligen Autoren beschrieben. Über den materiellen Mechanismus dagegen gibt es sehr wenig zu lesen. Das Verfahren wird ausserdem fast immer in einem kognitivistischen Jargon beschrieben, in welchem von neuronalen Netzen gesprochen wird, die - ob Nerven oder Maschinen - etwas tun. Ich beschreibe hier ein Verfahren, das ich anwende, wenn ich ChatGPT verwende. Mit ChatGPT kann ich das Verfahren einfach sehr effizient machen, was ja der Sinn von Werkzeugen ist. Ich kann das Verfahren aber auch jenseits von Computern beschreiben - auch wenn ich es ohne Computer nicht effizient verwenden könnte.
Das Verfahren besteht darin, einer bereits vorhandenen Schriftzeichenkette weitere Schriftzeichen anzufügen, so dass ein Text entsteht, den ein Menschen geschrieben haben könnte. Welches Schriftzeichen jeweils angefügt wird, beruht in diesem Verfahren darauf, welches Schriftzeichen in einer relativ grossen Menge von wohlgeformten Sätzen am meisten auf die bereits vorhandenen Schriftzeichen folgt. Dabei werden ein paar raffinierte Teilverfahren verwendet, auf die ich später noch genauer zurückkomme. Es geht im Wesentlichen darum, wie die Sätze, die als Vorbilder verwendet werden, so aufbereitet werden, dass sie die Wahl des jeweils nächsten Schriftzeichen ermöglichen.
Um das Verfahren anschaulicher zu erläutern, verwende ich hier anstelle von Schriftzeichen ganze Wörter, obwohl das Verfahren mit Wörtern viel schlechtere Resultate ergibt, als wenn ich es mit Schriftzeichen anwende. Ich verwende überdies eine sehr kleine Menge von Texten als Vorgabe. Das Beispiel stammt von M. Hielscher und ist unter www.soekia.ch zu finden. Ich verwende vier Märchen von Grimm und beginne meinen Text mit "Es war einmal ein". Dann kann ich - aufgrund der Vorlagen - unter ein paar anderen Wörtern "König", "Müller", "grüner" einsetzen, wodurch sich mein Satz verlängert und das Spiel von neuem beginnt. Wenn ich Müller eingesetzt habe, kommen als nächstes Wort "der" und "welcher" in Frage, die überdies hinter einem Komma stehen. Die einzelnen Wörter haben eine Gewichtung, je nachdem, wie oft sie in den Vorlagen vorgekommen sind. Im Beispiel wird "Müller" gewählt. Bei der zweiten Wahl haben "der" und "welcher" das gleiche Gewicht, ich verwende für die Wahl einen Würfel.
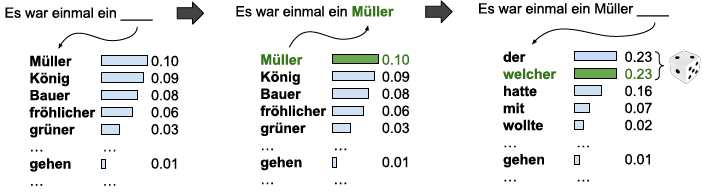
|
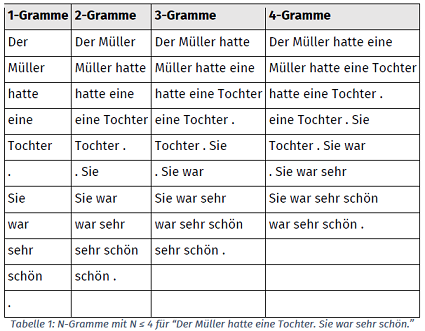
Die Gewichte der einzelnen Wörter schreibe ich in eine Tabelle, damit ich sie sofort finden kann. Diese Tabelle bezeichne ich als N-Gramm, dieses Wort stammt wohl von Googles Ngram-Viewer. Ich unterscheide verschiedene N-Gramme, die verschieden lange Sequenzen enthalten.
Die Sequenzen aus einem 4-Gramm kommen in einem Textkorpus logischerweise viel weniger oft vor als jene aus einen 1-Gramm. Deshalb wähle ich für meinen Text jeweils das N-Gramm mit der höchsten Zahl, in welchem ich meine Textsequenz finden kann. Das Verfahren kann erheblich komplizierter gemacht werden. Darauf will ich hier nicht eingehen. Ich will nur hervorheben, dass die N-Gramme keine Wörter enthalten müssen. Sie enthalten Schriftzeichenketten, die ich Token nenne. Ich zerlege beispielsweise die Textkette "wasisteingutersatz" in die Token "wasi stei gute rsat z.", die ich dann anstelle von Wörtern verwende. Wenn ich das Verfahren von Hand anwende, ist es mit Wörtern für mich viel übersichtlicher, wenn ich aber einen Computer verwende, spielt es natürlich keine Rolle, ob die Token Wörter sind.
|
![bild]()
|
Bildquelle: www.soekia.ch
|
Dass dieses Verfahren funktioniert, ist erstaunlich und nicht erklärbar. Es wurde wie beliebige andere Verfahren von Menschen gefunden und entwickelt. Jemand ist - wie und warum auch immer - auf die Idee gekommen, dem Brotteig Hefe beizugeben. Jemand hat gemerkt, dass man mit einem sich drehenden Magneten elektrischen Strom erzeugen kann. Und jemand hat gemerkt, dass man Texte hervorbringen kann, indem man dieses Verfahren verwendet. Nachdem das Verfahren entdeckt ist, kann jeder prüfen, ob und wie gut es funktioniert.
Wenn ich das Verfahren auf dieser einfachen Stufe überprüfe, staune ich darüber, dass es überhaupt funktioniert. Ich sehe aber natürlich auch, dass das Verfahren etwas ausgebaut werden muss, ohne dass ich sagen könnte wie. Da es aber ChatGPT gibt, ist auch klar, dass das Verfahren nicht nur im Prinzip funktioniert. Und wer schon andere Texte über ChatGPT gelesen hat, mag sogar anzweifeln, dass ich mit diesem Verfahren einen wichtigen Aspekt hervorgehoben habe.
Es geht hier aber nicht darum, ChatGPT zu erklären, sondern darum, ChatGPT als Modell für Textgenerierung zu erläutern, weil ich ChatGPT als Erklärung dafür verwenden will, was ich beim Schreiben mache. Deshalb will ich jetzt das Verfahren noch unter einem anderen Gesichtspunkt erläutern, der mir für das begriffliche Verständnis des Schreibens zentral scheint.
Das Generieren von Text - das ich jetzt anhand der Entwicklung eines Textes durch Anfügen von Schriftzeichen erläutert habe - ist als Verfahren in ChatGPT aufgehoben. ChatGPT ist ein spezieller Computer. Ich erläutere einen wichtigen Aspekt des Verfahrens dadurch, dass ich die Entwicklung dieses Computers, der umgangssprachlich als neuronales Netzwerk bezeichnet wird, erläutere. Dazu sage ich etwas über die Entwicklung des Computers überhaupt.
Als während des sogenannten 2. Weltkrieges die ersten Computer konstruiert wurden, gab es zwei sehr verschiedene Ansätze. Zum Einen einen bionischen Ansatz, der sich an der Natur orientierte und das Gehirn als Neuronales Netzwerk nachbauen wollte. Bionik (ein Kofferwort aus Biologie und Technik) heisst eine Vorstellung, nach welcher Konstrukteure die Natur als Vorbild nehmen (sollten). Eines dieser Konzepte beruhte auf der von W. McCulloch bestätigten Idee, dass neuronale Netze zur Berechnung von logischen Operationen verwendet werden können. Es gab verschiedene Projekte, in welchen neuronale Netzwerke entwickelt wurden, aber keines führte zu einem hinreichenden Erfolg. Es gab aber immer Ingenieure, die die Beschränkung der Von-Neumann-Rechner erkannten und sich - wohl unter bionischen Gesichtspunkten - weiterhin für neuronale Netzwerke interessierten.(5). Ich komme darauf zurück, wie sich der Erfolg viel später auf Umwegen eingestellt hat.
Der andere Ansatz orientierte sich an programmierbaren Automaten, wie sie J. von Neumann beschrieben hat, also an Maschinen, die in der Natur kein Vorbild haben. Der zweite Ansatz hatte durchschlagenden Erfolg, praktisch alle heutigen Computer sind von-Neumann-Maschinen. Neuronale Netzwerke dagegen werden bis heute keine verkauft. Auch ChatGPT ist kein neuronales Netzwerk, sondern eine programmierte Von-Neumann-Maschine. Speziell ist nur das Programm, das ein Teil dieser Maschine ist.
Neuronale Netzwerke funktionieren ganz anders als Von-Neumann-Rechner. Hier geht es aber nur darum, mit welchem Werkzeug ich bestimmte Verfahren effizienter machen kann. Die Technik, die als neuronales Netzwerk bezeichnet wird, ist nicht neu und sie ändert am beschriebenen Verfahren, in welchem Schriftzeichen gemäss deren Verteilungen in einem Textkorpus angeordnet werden, nichts. Das Verfahren wird technisch anders realisiert, so wie ein Benzinmotor ein Welle anders antreibt als eine Dampfmaschine oder ein Elektromotor. Es gibt ausserordentliche technische Erfindungen, die mich die Welt neu sehen lassen. Computer gehören zweifelslos dazu.
Computer heissen Computer, weil sie anfänglich hauptsächlich als Rechenmaschinen entwickelt und begriffen wurden. Die Erfinder hatten keine Ahnung, was man mit Computern ausser Rechnen machen könnte. Einer Legende nach sagte T. Watson, der die IBM schliesslich als Computerfirma gross gemacht hat, angesichts der ersten Computern, dass es auf der ganzen Welt einen Bedarf von vielleicht fünf Computern geben werde. Das widerspiegelt - ob als Zitat wahr oder nicht - dass man lange Zeit nicht wusste, wozu Computer - kommerziell - gut sein könnten. Die IBM war damals mit Schreibmaschinen und Lochkartenmaschinen sowohl mit Geräten zur Textherstellung als auch zur Datenverarbeitung ein weltweit führender Konzern.
Die Computer-Erfinder sprachen sehr früh von intelligenten, denkenden Maschinen. Sie bauten, um das zu illustrieren von Anfang an Schachcomputer. Aber wer sollte schon einen Schachcomputer kaufen? Und davon unabhängig ist Schach ein Ergebnisspiel, das vom Spieler nur Wissen, aber kein Können verlangt, während sich Fussball dieser einfachen Logik entzieht, weil die Umsetzung der Spielzüge vom Können der Spieler abhängig ist. Wenn ich einem Schachspieler sage, welcher Zug er machen muss, macht er das, wenn ich einem Fussballer sage, wohin er den Ball kicken muss, trifft er manchmal oder eher sehr selten. Beim Schach ist zu jedem Zeitpunkt ein bestimmter Zustand bezüglich der Verteilung der noch vorhandenen Figuren auf dem Brett gegeben und ausserdem natürlich, bei welchen Spielzuständen das Spiel gewonnen ist.
Ein Schachspieler kann sich ganz viel überlegen und vorausberechnen, welche Folgen sein jeweils nächster Zug haben könnte. Mit immer leistungsfähigeren Prozessoren wurden immer bessere Berechnungen von Spielverläufen möglich, aber der entscheidende Durchbruch ist mit dieser Technik nie gelungen. Es gibt aber eine andere Möglichkeit, Schach zu spielen. Wenn ich sehr viele Partien von Grossmeistern kenne, kann ich zu jedem Zustand auf dem Brett in meinem Gedächtnis abrufen, welche Züge bei den Meistern in genau dieser Situation zum Sieg geführt haben. Weil mein Gegner dann nach meinem Zug durch seinen Zug den Zustand auf dem Brett wieder verändert, habe ich wieder eine Situation, die ich mit meinem Gedächtnis vergleichen muss. Darin besteht ein aussichtsreicher Weg zu gewinnen - wenn mein Gedächtnis gut genug und schnell genug ist.
Diese Art Spiel - die eben kein Spiel, sondern Wettkampf ist - kann ich nicht wie einen Mechanismus beschreiben. Die sich folgenden Zustände sind lose gekoppelt, sie folgen sich - auf der beobachteten Ebene - nicht zwingend, sie sind kontingent.
Umgekehrt gehörte das Übersetzen von Texten, das sich mittlerweile auch als eine der wichtigsten Funktionen, die durch Computern erfüllt werden, erwiesen hat, zu den ersten Anliegen, die für Automaten formuliert wurden. S. Ceccato beispielsweise hat kurz nach dem Krieg von der amerikanischen Armee viel Geld bekommen, weil er eine Übersetzungsmaschine versprochen hatte, obwohl er noch gar keine Computer kannte. Man hat lange Zeit versucht, Computer zu konstruieren, die wie Menschen übersetzen. Dazu hätte man aber wissen müssen, was Menschen tun, wenn sie übersetzen. N. Chomsky hat dazu die kognitivistische Psychologie erfunden, die aber nicht nur in Bezug auf Übersetzungen keinen brauchbaren Fortschritt brachte, sondern durch eine blöde Kritik am Behaviorismus die Psychologie insgesamt auf den Kopf gestellt hat.
Die klassischen Von-Neumann-Maschinen erfüllen bestimmte Funktionen ausserordentlich gut, auch wenn sie für bestimmte Aufgaben, eben etwa das Übersetzen, lange Zeit kaum zu brauchen waren. Rückblickend kann man leicht erkennen, dass das nicht an der Von-Neumann-Architektur lag, die wir ja immer noch verwenden, sondern daran, wie sie programmiert und damit begriffen wurde. Die Mathematiker, vorab A. Turing und J. von Neumann lenkten die Aufmerksamkeit auf von Anfang an auf eine bestimmte Art von Algorithmen bestimmt war, in welchen das Erkennen von Mustern genannten Konfigurationen - wie sie für Schach typisch sind - keine Rolle spielte. Auch darin zeigt sich ein nicht adäquates Verständnis der Maschine, die als Computer bezeichnet wurde.
Das zeichnet sich auch in der Entwicklung der Programmiersprachen ab. Die erste Programmiersprache wurde Fortran (FORmula TRANslation) genannt, weil sie auf mathematische Formeln ausgerichtet war. Fortran entstand 1953 noch unter der Vorstellung, dass Computer "Rechner" sind. Erst als man realisierte, dass Computer vor allem in der Datenverarbeitung verwendet werden, hat man 1960 Cobol entwickelt. Während Fortran noch von IBM entwickelt wurde, wurde Cobol vom amerikanischen Verteidigungsministerium entwickelt. Die sogenannte Datenverarbeitung hat dann wieder für Jahrzehnte das Bild der Computer, die jetzt EDV-Anlagen genannt wurden, geprägt.
Auch die Datenverarbeitung verstellte durch den Formularmodus den Blick auf Text. Als ich 1978 auf einer PDP das Programmieren lernte, erkannte ich sofort, dass ich alle Texte mit grossem Vorteil auf dem Programmeditor schreiben konnte, der so für mich als Textprogramm fungierte. 1980 hatte die Uni Zürich dann das erste eigentliche Textprogramm "Script" auf einer VMS-Maschine allen Studenten zur Verfügung gestellt. Aber wirklich verbreitet hat sich Textsoftware erst auf den PCs, die in den ersten Jahren noch nicht für jedermann erschwinglich waren.
Auch die sogenannte Textverarbeitung - ein Unwort eines IBM-Managers für Text-Software - veränderte die Sicht auf die Von-Neumann-Rechner nicht wesentlich. Zwar wurde offensichtlich, dass Computer nicht zum Rechnen verwendet werden, aber sie wurden immer noch konventionell programmiert. Ein eigentlicher Durchbruch ergab sich mit der Graphik, der Bildsoftware und der Maus. Damit wurde die serielle Logik von Text aufgebrochen. Bilder wurden als pixelbasierte Raster aufgezeichnet. Damit verbunden entstanden neue Anliegen, nicht zuletzt die Bilderkennung.
Die Bilderkennung, die - komischerweise - sehr oft als Mustererkennung bezeichnet wird, rückte den Focus von der seriellen Symbol"verarbeitung" weg. Auslöser mögen die sogenannt digitalen Kameras gewesen sein, in welchen Bilder zu Pixelmengen geworden sind. Man realisierte, dass das Auge auch mit solchen "Daten", die eben keine waren, umgehen muss und erinnerte sich an die neuronalen Netze von W. McCulloch. W. McCulloch hatte in der Anfangszeit der Computer gezeigt, wie mit neuronalen Netzen ein Logikkalkül realisiert werden kann, und was wohl noch wichtiger war, wie sich damit die Wahrnehmung oder Segmentierung von Bildern beschreiben liess. Die Technik nahm damals (und bis heute) mit der Von-Neumann-Maschine und der Schaltalgebra einen anderen Weg, der aber an den neuen Aufgaben scheiterte.
In der 1950er Jahren gab es rege Diskussionen D. Hebb, K. Lashley, M. Minsky und andere trafen sich auf der Dartmouth Conference. F. Rosenblatt stellte den Mark I Perceptron, der mit seinem 20 × 20 Pixel großen Bildsensor bereits einfache Ziffern erkennen konnte. 1960 benutzte B. Widrow ADALINE ein neuronales Netz zur Echtzeit-Echofilterung bei Analogtelefonen. 1961 stellte K. Steinbuch die assoziative Speicherung vor.
Mangels Technologie blieb das neuronale Netz eher philosophisch interessant. In den 1970er Jahren startete mit dem Werk von T. Kohonen und etwas später jenem von J. Hopfield, der 1985 eine Lösung des Travelling Salesman veröffentlichte, ein neues Technologieprojekt mit dem reissenden Titel des maschinellen Lernens. Die schon länger bekannte Backpropagation of Error als Verallgemeinerung der Delta-Regel machten nicht linear separierbare Probleme durch mehrschichtige Perceptrons lösbar. M. Minskys Einwände waren widerlegt.
Die hier interessierende Funktionsweise des ChatGPT-Computers (das Verfahren) besteht darin, aufgrund von vielen spieltheoretischen Zustandsfolgen abzuschätzen, welche Zustände häufig auf welche Zustände folgen, so dass tendenziell möglich wird, vorauszusagen, welcher Zustand auf welchen folgt. Bei einem Mechanismus im engeren Sinn ist die Zustandsabfolge definiert oder anders ausgedrückt, fest gekoppelt. Eine Maschine macht immer dasselbe und ein Automat, reagiert auf einen bestimmten Zustand immer gleich. Das ist der Witz der mechanischen Regelung. Beim neuronalen Netzwerk ist diese Koppelung aufgehoben.
Technisch entscheidend war, dass etwa ab 2000 die neuronalen Netzwerke nicht mehr gebaut, sondern auf Von-Neumann-Maschinen simuliert wurden. Allmählich stellten sich - beim Handschriften erkennen oder bei der Schachweltmeisterschaft - Erfolge ein, die als DeepLearning bezeichnet wurden. Es ist offensichtlich, dass es eine neue Computertechnik ist. Eine ganz andere Frage ist, was diese Technik mit Lernen zu tun hat.
Ich erläutere was als DeepLearning bezeichnet wird Dabei ist sehr wichtig zu sehen, dass DeepLearning nichts mit dem zu tun hat, was in der Umgangssprache mit Lernen bezeichnet wird. Die Vorsilbe Deep soll anzeigen, dass des sich nicht um Lernen handelt, so wie die Vorsilbe Erd- bei Erdbeeren - darauf verweist, dass Erdbeeren sind keine Beeren sind. Beeren wachsen nicht auf der Erde, sondern an Sträuchern.(6)
Umgangssprachlich sage ich, dass ein Kleinkind die Muttersprache lernt. Aber dabei ist mir natürlich bewusst, dass ich von etwas ganz anderem spreche, als dem, was Schüler in der Schule beim Lernen tun. Gemeinhin wird das Unterscheiden von Gegenständen im Gesichtsfeld eines Kleinkindes nicht auf einen Lernprozess zurückgeführt. J. Piaget etwa problematisiert die Objektpermanenz, aber nicht, das Objekte als solche wahrgenommen werden. Das Kleinkind kann Objekte erkennen, ohne es gelernt zu haben. Es muss laut J. Piaget lernen, dass die Objekte auch vorhanden sind, wenn es die Objekte nicht sehen kann. Aber auch dazu sagt J. Piaget nicht, wie dieses Lernen vor sich gehen soll. Lernen heisst in diesen nicht reflektierten Sinn, dass eine Fähigkeit vorhanden ist, von der man keine Idee hat, woher sie kommt. N. Chomsky postulierte, dass solche Fähigkeiten im Erbgut vorhanden sind.
Über ChatGPT kann man auf beliebig viele Arten nachdenken. Insbesondere kann man ChatGPT, wie es viele Technikphilosophen und Politiker tun, als gesellschaftliche Herausforderung betrachten. Dabei betrachtet man aber nicht ChatGPT, sondern Auswirkungen, die man ChatGPT zurechnet. Lehrer können sich darüber Sorgen machen, dass sie nicht mehr wissen können, ob die Texte, die sie korrigieren, von den Schülern selbst geschrieben wurden. Solche Erwägungen spielen hier keine Rolle, mir geht es hier darum ChatGPT als hochentwickeltes Werkzeug zur Textherstellung zu begreifen, anhand dessen ich verstehen kann, was ich beim Schreiben eigentlich mache. Deshalb habe ich bisher bestimmte Aspekte der Funktionsweise von ChatGPT hervorgehoben.
Ich betrachte ChatGPT als hoch automatisierte Maschine, deren Entwicklung mir zeigt, was ich früher beim Schreiben von Hand machen musste
Ich habe das Textherstellungsverfahren als kontinuierliches Anfügen von Schriftzeichen beschrieben und Aspekte der dabei verwendete Technik behandelt.
Weil ich ChatGPT hier als Modell für Textherstellung verwende, habe ich bisher einige Aspekte von ChatGPT, die gemeinhin nicht so beobachtet werden, mir aber wichtig sind, erläutert. Ich habe das Textherstellungsverfahren als kontinuierliches Anfügen von Schriftzeichen beschrieben und Aspekte der dabei verwendete Technik behandelt.
Insbesondere habe ich dabei hervorgehoben, dass es sich bei ChatGPT um einen konventionellen Computer handelt, der allerdings auf eine spezielle Art programmiert ist, bei welcher der Programmierer die Zustandsabfolgen und mithin den Output des Computers nicht festlegt, sondern lediglich ein Verfahren, das auf stochastischen Verteilungen beruht. Ich habe damit einen Mechanismus beschrieben, mit welchem ich ein spezifisches Phänomen hervorbringen kann. Das ist genau das, was ich von einem Modell erwarte, das ich als Erklärung verwende.
Ein entscheidener Gesichtspunkt meiner Erläuterungen besteht darin, die verwendetet Sprache zu reflektieren. Es macht einen grossen Unterschied, ob ich sage, dass ein Computer rechnet, oder ob ich sage, dass ich mittels eines Computers rechne. Auch die Bezeichnung Computer oder Rechner wirft ein eigenartiges Licht auf die gemeinte Maschine, die ein programmierbarer Automat ist. Ich verwende diesen Automaten praktisch nie zum Rechnen, weshalb sollte ich ihn also als Rechner bezeichnen?
Natürlich sind Namen arbiträr. Es gibt keinen Grund dafür, dass der Hund Hund oder der Apfel Apfel heisst. Genauso kann irgendein Ding Computer heissen. Es ist eine sprachliche Konvention. Es ist aber wichtig, diese zufällige Konvention zu erkennen, um nicht ganz unsachliche Vorstellungen daraus abzuleiten. Die Ingenieure verwenden sehr oft Ausdrücke, die in der Alltagssprache bereits einen Sinn haben, um etwas ganz anderes zu bezeichnen, oft auch, weil sie nicht recht verstehen, was sie erfunden haben. Sie erfinden eine Maschine und meinen, sie hätten Natur nachempfunden. Sie sprechen dann von denkenden, lernenden oder wie schon C. Babbge von einer analytischen Maschine. A. Turings Intelligenztest spricht Bände dazu.(7)
xxx
ChatGPT wird trainiert. Das Training bewirkt, dass zunehmend bessere Texte hervorgebracht werden. Ich habe ein paar Aspekte
Auch hier gilt, dass das Wording unsinnnig ist:
ChatGPT macht keine Übungen wie ein trainierender Sportler !!
Anmerkungen
1) Das Sprechen scheint in einer bestimmten Hinsicht komplizierter, weil es keine Wörter zeigt. Ich mache keine erkennbare Zwischenräume zwischen den Wörtern. Das ich Nachrichtensprecher besser verstehe als Schauspieler, die im Film mit anderen Schauspieler sprechen, kann ich so nicht erklären. Ich verstehe englische Aussagen leichter, wenn sie von Fremdsprachlern gemacht werden. Ich glaube, das hat nicht mit dem Wortschatz zu tun, sondern mit einer bewussteren Formulierung; Akzent heisst wohl Akzentuierung von Wörtern, die ein Muttersprachler so nicht macht.
Das spielt wohl auch der Schulung der Nachrichtensprecher eine Rolle oder ist ein generelles Verhalten beim Vortragen/Vorlesen. (zurück)
2) Eine ganz andere Frage, die ich hier nicht behandeln will, ist, weshalb es überhaupt Schulen gibt.
Kurz: Ich nehme an, dass es damit zusammenhängt, dass Lesen und Schreiben als Explikation des Sprechens durch Nachahmen sehr unwahrscheinlich ist, weil es im praktischen Leben nicht hinreichend oft vorkommt. Dazu müsste ich die Geschichte der Schule kennen. In der eigenen Erfahrung, also in einer Zeit, in welcher meine Eltern lesen und schreiben konnten, habe ich keine Situationen erlebt, die ein Nachahmen möglich oder wahrscheinlich gemacht hätten.
Eine wunderbare Geschichte dazu erzählt B. Schlink in seinem Roman Der Vorleser. Eine Frau, die bis dahin weder lesen noch schreiben konnte, bekommt im Gefängnis von ihrem Geliebten Tonbänder, worauf er ihr Bücher vorliest. Sie beschafft sich diese Bücher in der Bibliothek und bringt sich das Lesen und Schreiben bei, indem sie die gesprochenen Wörter mit dem Text in den Büchern vergleicht.
Sie reproduziert damit das Entziffern von Hieroglyphen, wobei sie natürlich vorab weiss, dass die Vorlesungen aus bestimmten Büchern stammen.
Das wird ein grosses Thema in meinem Buch Schrift-Sprache über das Herstellen von Artefakten, die Texte sind.
(zurück)
3) "Die Produkte der Ingenieure imitieren nicht die Natur. Unsere Flugzeuge imitieren im Unterschied zum schliesslich abgestürzten Ikarus keineswegs die Vögel. O. Lilienthal, einer der Erfinder des Flugzeuges, schrieb anfänglich irritiert durch die Metapher, die er mitbegründete: "Mit welcher Ruhe, mit welcher vollendeten Sicherheit, mit welchen überraschend einfachen Mitteln sehen wir den Vogel auf der Luft dahin- gleiten! Das sollte der Mensch mit seiner Intelligenz, mit seinen mechanischen Hilfskräften, die ihn bereits wahre Wunderwerke schaffen liessen, nicht auch fertigbringen? Und doch ist es schwierig, ausserordentlich schwierig, nur annähernd zu erreichen, was der Natur so spielend gelingt". Die in der nicht bewussten Metapher begründete Verwechslung ist offensichtlich. "Mit überraschend einfachen Mitteln auf der Luft dahingleiten" sehen wir natürlich nicht die Vögel, sondern die - wenn man überhaupt Vergleiche anstellen wollte - extrem primitiven Gleiter, die O. Lilienthal konstruiert hat. Auf die wirkliche Konstruktionstätigkeit bezogen, schrieb er aber bereits während der langjährigen Entwicklungsphase des Flugzeuges, also lange bevor die ersten Flugzeuge wirklich flogen: "Ob nun dieses direkte Nachbilden des natürlichen Fluges (des Vogels) ein Weg von vielen oder der einzige ist, der zum Ziel führt, das bildet heute noch eine Streitfrage. Vielen Technikern erscheint beispielsweise die Flügelbewegung der Vögel zu schwer maschinell durchführbar, und sie wollen die im Wasser so liebgewonnene Schraube auch zur Fortbewegung in der Luft nicht missen". (Todesco, 1992:200). (zurück)
4) Noch ausformulieren und einsetzen:
Ein Lektor hat einmal einen Text von mir, der in einem Sammelband erschienen ist, im Auftrag der Herausgeber überarbeitet. Er hat meinen Text nicht verstanden, oder genauer, er hat den Text ganz anders verstanden als ich. Er hat viele einzelne Sätze durch schönere Sätze ersetzt, die dem Leser das Lesen erleichtern sollten. Dabei ist der Text tatsächlich lesbarer geworden, aber er hatte eine neue Bedeutung bekommen. Das Problem hatte ich auch bei einer Übersetzung ... wo ich aber eher damit gerechnet habe ... Kinder lernen auch schönere Sätze ... wie Schönschreiben .. unabhängig davon, was die Sätze bedeuten. (zurück)
5) Ein berühmtes Projekt war jenes von H. von Froerster, das als Biological Computer Laboratory bezeichnet wurde. (zurück)
6) Erdbeere oder wie adjektivische Voranstellungen (Präfix, Kompositum) zu interpretieren sind:
Auf irgendeine unverstandene Art versteht jeder (der Deutsch spricht), was mit dem Ausdruck "Erdbeeren" gemeint ist. Auf dem Markt kann ich sagen, ich hätte gerne Erdbeeren, und ich kriege Erdbeeren. Der Referent des Ausdruckes ist gemeinhin (aufgrund einer mehr oder weniger impliziten Vereinbarung) bekannt. Erd-Beeren sind aber keine Beeren, WENN man die Sache biologisch betrachtet, (also eine andere Perspektive wählt). Beeren wachsen dann nämlich gerade nicht bei der Erde, sondern an Sträuchern und haben wässeriges Fruchtfleisch und Kernen. Die adjektivische Vorsilbe sagt also, dass es sich gerade nicht um eigentliche Beeren handelt. Ich erkenne darin ein generelles Phänomen der deutschen Sprache. Vorsilben reflektieren die Position oder die Perspektive des Sprechers (beispielsweise sage ich heraus oder hinaus). Vorangestellte Eigenschaften dienen der begrifflichen Spezifizierung sehr verschieden. Erd-Beere heisst sowohl "Beere nahe der Erde", wie auch "Nicht-Beere".
(zurück)
7) Der Test von A. Turing .. wie kann man Menschen täuschen ...
(zurück)